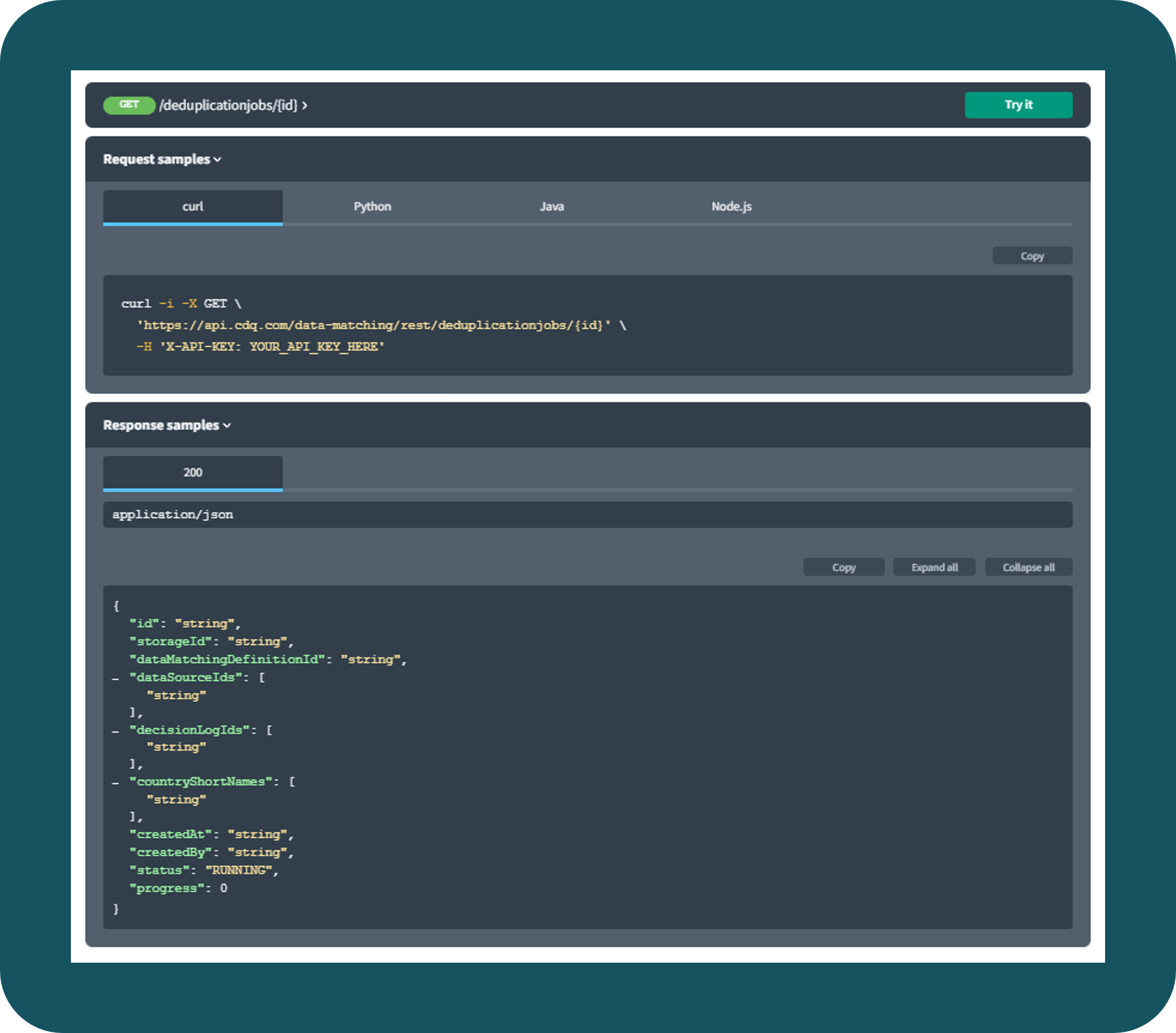
Data Deduplication
Get rid of master data duplicates to keep your operations undisrupted.

Why data deduplication really matters:
are unintended duplicates
duplicated SAP business partner
in our customers organizations
Sounds familiar?
-
Your procurement is unable to consolidate spends per supplier correctly...
-
Better prices or payment terms with vendors are out of your reach...
-
Insolvent supplier or customer was blocked, but their duplicate remained active...
-
Your customer services assume too small revenue due to hidden relevance...
-
Post merger integration required ultra fast consolidation of customers and suppliers...
-
Implementation of joint processes across merged businesses took more time, money and nerves than expected...
Sustainable approach to combating master data duplicates
With a focus on accuracy, flexibility, and continuous improvement, CDQ supports your deduplication efforts while proactively avoiding future duplicates.
- Flexible access: via user-friendly web applications or via APIs, designed to handle more than 1M records with ease, seamlessly integrated into your system, including SAP MDG and S4/HANA.
- Deep domain knowledge: service implemented with deep domain knowledge for business partner data. Versatile for various data types.
- Country-specific configurations: ready-to-use business partner matching configurations tailored to different countries, ensuring accurate matching based on local requirements.
- Customization: full flexibility to customize matching configurations, including data preparation using cleaners. Multiple comparison algorithms support you to meet specific business needs (e.g., Levenshtein comparator, phonetic comparison, and more)
- Continuous improvement: machine learning (AI) enhances matching classification and scores continuously, for better accuracy and adaptability to changing data patterns.
- Rule-based Golden Record consolidation: consolidation of matched records into a single augmented, enriched record, for data integrity and completeness.
Do you know the impact of duplicated master data records on your business?












Deduplication powered by CDQ
At the core of CDQ deduplication process lies the matching configuration. It includes essential components like Mapper to specify the characteristics and choose attributes used in matching, Weights to control influence of each attribute on the overall score, Comparators to define the method for comparing single attributes, a Threshold for similarity, and Cleaners for matching optimization and increased accuracy.
Furthermore, for matching groups that have been identified, you can define consolidation rules to generate golden records meeting your requirements.
Click here for more details of CDQ configuration for best matching results

7 steps towards deduplication
Upload data

Submit data to the CDQ Cloud
Define data model

Map attributes of your data model to attributes of the CDQ data model and ensure that CDQ matching engine understands specific fields.
Define matching configuration

Configure the matching engine according to the data to be analyzed. With no effect on database, configuration can be changed for each matching job
Find similar records

Comparison of all records against each other, according to the matching configuration
Build matching groups

Grouping of most similar records. Matching score is more important than group size (matches are sorted by score, then grouped)
Create Golden Records

For each matching group a Golden Record is created, summarizing a matching group by the majority of similar values.
Create duplicate report

Provides an excel report with all matching groups and not-matched records.
Combating duplicates with CDQ

In the project, we not only eliminated thousands of duplicates, but developed a sustainable cleansing approach, including global duplicate definitions, a cross-company review process and an innovative review tool
How CDQ can help you
- With our advanced algorithms and tailored data quality rules you'll reduce costs associated with data redundancy and inefficient processes.
- Identify and flag records associated with natural persons, ensuring GDPR compliance and mitigating legal risks.
- Ensure smoother M&A projects and seamless customer experience by consolidating customer and supplier data, and enhance cross-selling opportunities.
- Prepare for S/4HANA migration with clean data, leading to lower costs and improved system performance.
- Customize your deduplication process by deciding whether to generate a golden record based on your organization's needs.
- Use extensive customization options, including attribute mapping, weights, comparators, and thresholds, to tailor your deduplication process to your specific requirements.
- Leverage country-specific configurations to address variations in names and addresses, ensuring data accuracy across different regions.
Full flexibility in configuration for your exact needs
Matching configuration defines which attributes are to be compared (which comparator should be used for which attributes), which impact identical or different values of these attributes have on the matching score (confidence scores, how values should be temporarily transformed (which cleaners should be used), which threshold the matching score of potential matches should be exceeded to be considered a duplicate.
CDQ offers a fully-flexible configuration
- Any set of attributes can be used for identifying duplicates
- Cleaners and comparators can be individually configured
- Thresholds can be individually configured
You can use standard configurations and optimize them iteratively for their specific use case
Cleaners
For each input data field, a cleaner can be used. A cleaner transforms or normalizes data of the field before it is compared. Thus, cleaners help to improve match scores by removing characters or accents which are not meaningful in the matching context.
Standardize and harmonize for better matching results.
These cleaners are used to normalize values, i.e. remove accents, whitespace, and case differences:
- Lower case normalize: Most widely used cleaner. It lowercases all letters, removes whitespace characters at beginning and end, and normalizes whitespace characters in between tokens. It also removes accents, e.g. turning é into e, and so on.
-
Non-character cleaner: Removes any characters that are not latin characters including numbers.
-
Replace cleaner: Replaces strings by other strings. Patterns may also comprise regular expressions, character case can be ignored.
-
Strip nontext characters cleaner: Removes non-text characters. Specifically it strips control characters and special symbols
-
Trim cleaner: Trims whitespace characters at the beginning and end of the input string.
-
Regular expression cleaner
E.g. City cleaner, Legal form cleaner etc:
Legal Form Cleaner
-
Special cleaner for business partner names. The cleaner identifies a legal form in the input string and cuts it
-
Example: In CDQ AG Factory St. Gallen , AG is identified as legal form and only CDQ remains for matching.
-
More than 1‘000 legal forms worldwide with more than 2‘500 variations of abbreviations (Limited, Societe Anonyme, Aktiengesellschaft, Incorporation, etc.)
International phone numbers cleaner
-
Standardizes phone numbers to one common international format, so that e.g. the following numbers are represented identical
-
0049 55301400,
-
+49 55301400,
-
49 55 301400,
-
+49 (0) 55301400
Country cleaner
-
Special cleaner for removing country names from an input value In some cases it is required to match values such as CDQ AG and CDQ Deutschland AG
-
Takes the input value and searches for any term that represents a country. This information is then removed from the input, so that just CDQ AG is compared with CDQ Deutschland AG
Comparators
Comparators compare two string values and produce a similarity measure. To compare different kinds of values differently, the CDQ duplicate identification engine can use the following comparators among others:
Apply individual comparisons for any attribute for highly accurate matching
The Exact Comparator, categorized under "String Comparison," delivers precise data comparisons. It treats attributes as identical only in case of exact congruency. For example, when comparing "ABC Corporation" to "ABC Corp," it treats the strings as different and thus lowers the overall score.
"Geospatial Comparison" is ideal for location-based data. It calculates the distance between geographic coordinates to determine location proximity accurately. For instance, when comparing the coordinates of New York (Latitude 40.7128, Longitude -74.0060) and Los Angeles (Latitude 34.0522, Longitude -118.2437), it provides the distance between these locations on Earth's surface.
-
Categorized as "Phonetic Comparison," the Soundex Comparator utilizes a phonetic algorithm to compare textual data based on their pronunciation. It excels at recognizing similar-sounding names or terms, enhancing data accuracy. For example, it would identify a similarity between "Smith & Sons Co." and "Smyth and Sons" due to their phonetic resemblance.
-
The Metaphone Comparator employs the Metaphone phonetic algorithm to compare textual data. It transforms text into phonetic representations, making it effective for identifying similar-sounding names and terms. For example, it would compare "Phoenix Electric" and "Fenix Elektrik" based on their phonetic representations, enhancing data accuracy during comparisons.
-
Jaro Winkler Comparator specializes in comparing short strings like names. It calculates the Jaro Winkler distance, a dedicated metric for deduplication. When comparing "Johnson & Johnson" and "Johnston & Jonson," it produces a Jaro Winkler distance score to indicate their similarity.
-
Levenshtein Comparator quantifies string similarity by measuring the number of edit operations needed to transform one string into another. This makes it highly reliable for fuzzy string comparisons. For example, when comparing "Google Inc." to "Goggle Incorporated," it counts the edit operations required.
-
Longest Common Substring Comparator offers in-depth analysis by identifying the longest common substrings. It repeatedly drills down to the smallest shared elements. When comparing "Tech Solutions Group" and "Solutions Group Inc.," it identifies the longest common substring, such as "Solutions Group."
Q Gram Comparator: The Q Gram Comparator utilizes n-grams of field values to calculate similarity. It excels in scenarios where token order doesn't matter. For instance, comparing "Microsoft Corporation" and "Corp Microsoft" using 2-grams, it calculates their similarity.
Business benefits of good master data
Duplicate entries in your customer and supplier databases hold back reliable analyses and lead to higher maintenance efforts and process costs.
With CDQ you can detect duplicates in large datasets by checking against more than 2,500 data quality rules and combined with your customized matching confguration. Learn how easy cleansing and augmenting of data records can benefit your business.

Solutions recommended for you
More trust: Assess data
- Find out how much of your existing data is correct, complete and fit-for-use.
- Rule-based assessment of data quality reveals any duplicates and errors across your business partner datasets.
- Our platform is open to all connected registers – including audit-trail.
More speed: Create data
- Create new business partner data records fully correct and fit-for-use from the start.
- Rule-based validation of onboarded record prompts missing or incomplete information and qualifies tax identifiers against trusted authority services.
- Ready for use in S/4 HANA and SAP MDG Cloud
More efficiency: Maintain data
- Continuously monitor correctness of an existing business partner.
- Automated ongoing validation ensures you are always working with the most up-to-date information.
- Any changes of data records are prompted to you in the system and through push messages.
You may also like

Boost Data Quality for SAP S/4HANA: The Role of Customer Vendor Integration (SAP CVI)
How benchmarking can help you find out! Data quality benchmarking helps to identify gaps in an organization's data quality processes and target their…

Augmenting business partners into trusted Golden Records
Golden Record: the fundamental concept that ensures the integrity and consistency of your business partner information. At its core, a golden record is the…

Good data vs. bad data: welcome to Data-City
What if Gotham City was a real place, and you lived there every day? Just imagine Data City: a metropolis under constant threat from all the worst villains.…




